
I started this article with the hopes of confronting a few misconceptions about Deep Learning (DL), a field of Machine Learning that is simultaneously labelled a silver bullet and research hype. The truth lies somewhere in the middle, and I hope I can un-muddy the waters — at least a little bit.
Importantly, I hope to clarify some processes to attack DL problems and also discuss why it performs so well in some areas such as Natural Language Processing (NLP), image recognition, and machine-translation while failing at others.
Deep Learning is Not a Dark Art
Media often portrays Deep Learning as a magical recipe to the end of the world or the solution to all life’s problems. In reality, it is anything but. Moreover, while DL has its fair share of strange behaviour and unexplained results, it is ultimately meritocratically driven. By demanding proof and reasoning in your development process, you can build a robust framework amongst the unlimited number of model permutations.

Everything Has A Purpose (Most of the Time)
One of the first problems I see new practitioners exhibit is smashing together a few LSTM (Long Short-Term Memory) layers, a GRU (Gated Recurrent Unit) layer, and a few convolutional layers for good measure, and sitting and waiting for the magic results. Then looking on in frustration at their models 5% accuracy metric. As I will discuss later, DL requires a much more reasoned approach.
By adopting a methodology based on the integration of data, network design, and curiosity, you will be able to produce phenomenal results. I take time every day to read new papers and articles on the latest methodologies and constantly see clever ideas driving new designs.
In DL, different layers serve different purposes. This is a simple idea that is often lost among those new to the field. Moreover, while I do experiment plenty during the design process, I always test along a line of thinking. There should be a reason (or at least a hypothesis) for adding complexity. It should be checked against a measurable metric, and only then should I accept it into the ultimate design. Additionally, you should favour simpler models over complex models given that they achieve the same results. I consistently test smaller networks, either fewer neurons or fewer layers and compare them to my best design. Smaller systems also mean faster training (in some cases several orders of magnitude), which means more iterations and better ultimate design.
There are tools that you can create to test a new thesis on both small and large networks, and that understanding will drive your overall knowledge of network design. As you work more and more with Neural Networks, you will better understand what drives its behaviour for a particular task. You begin to develop a map in your head of what to try and when, but only if you have the right metrics and processes to understand along the way.
The Design Process
I think of the design process the same way a child tries to build a tower of bricks, testing along the way. Poking, prodding, failing, but always testing. Is the second layer of the tower too wobbly? Should I change the base? It is helpful to think of having a limited number of blocks. The smaller the neural network, the faster you can train it, and the quicker you can test it. Only add complexity when needed.
In DL, the problem has an infinite number of possible solutions — thus, you are dealing with networks that can simulate a nearly infinite set of formulae. While the final result may be discrete, neural networks live in a world of continuous numbers. Complexity tends to explode quickly, and increased complexity demands increased control. I try to build my networks in the same way I build a new data project. For example, a simple exploratory data analysis pipeline could be:
Ingest Data → Clean Data → Transform Data → Present Data
Each of these overall blocks could involve many different steps. If I move through the process without ensuring the quality of the upstream processes, the whole system is going to fail. So I test along the way. I test everything — inputs, outputs, classes, functions. I make sure everything works individually and then together. I know this is not a groundbreaking idea, but it is worth pointing out. Once I have got one process working I move to the next and build upon it.
In Deep Learning, I start by creating the simplest model. When approaching a text-classification task, I’ll start with the simplest version of an Embed-Encode-Attend-Predict model. After seeing how that base model works, I’ll start building upon it. That could involve increasing the size of hidden layers, deepening the network, merging new networks, changing activation and initialisation, augmenting the text with Part-Of-Speech tags or other numerical data. I might have several neural networks feeding into each other to serve a different purpose, or change how the data is processed, or the text is vectorised. The list goes on.
With each step, I baseline it against my original model and my iterations along the way. This process allows me to look back at the evolution of my model, understand where it got better (or worse), and inform future iterations of the design; Always getting closer to the global minimum.
Be The Master of Your Data
Before you start experimenting with your DL model, it is essential to understand where the value lies for a given problem. There is a simple hierarchy to follow:
Data is greater than model design, and model design is greater than parameter optimisation.
If company A has ten times the data of company B, no model in this world will allow company B to best company A’s models. The same idea applies to data quality.
If I spend weeks developing a model on the back of weak data quality, it will underperform a model that I built in a few days on the back of high-quality data. Always ask yourself if you can get more data before you spend weeks on modelling. Perhaps you can change your preprocessing steps to improve the quality of the data you already have. This will often lead to quicker performance gains than one through model tweaks alone.
Not only do you need high-quality data, but you also need a deep understanding of it. You should spend time developing tools to analyse, present, and study your input data. You should build metrics and analysis tools to understand the predictions of your model. Avoid thinking of data as merely an input. All data has hidden features that hold immense predictive power if you can extract them. Sometimes you have to do this yourself, other times you can develop your DL model in a way that it can do this on its own. Think of your data as an input to a cryptographic algorithm — but instead of encrypting a text or email, it is encoding the way the world works. Each data point is a clue to better understanding.
Text classification in NLP is a perfect example. You are given a corpus of hundreds or thousands of words, and each text has a class or multiple classes. Maybe this class is positive, negative, or neutral, and perhaps you have hundreds of complex and intricate classes. Either way, the text is the code that we use to determine our output.
When you stop thinking about your input as only words, it becomes immensely valuable and opens the door to unbelievable results. This sort of thinking led to developments from word vectors to word-level models, to sentence-level models, to paragraph-level models. Each of these implementations is based on how human-level understanding works and manifested itself in performance gains.
Spend Time With Domain Experts
This ties closely into the previous section and perhaps is even more important-spend the time to talk with people with domain knowledge. Discuss your results with them, discuss the data with them. Involve them in the design process.
You would be shocked how often the effort of discussing your model’s design philosophy and the outputs of your model results in quick wins. Those quick wins often translate to sharp increases in accuracy. Sure, this involves a time investment to educate them on the intuition and conceptual understanding of Deep Learning, but it has always been worth it for me. If you do not have a domain expert available, spend the time to learn on your own. Avoid trying to build a DL model for a problem you do not understand.
Remove the idea that Deep Learning is like feeling your way through a maze with no lights on. In reality, you can tackle Deep Learning by following the right methodology and trying to solve the correct problems. You should always be asking yourself why.
While the methodology I am about to describe may sound counter-intuitive to the idea of metrics-driven design, I find it builds understanding in the best way; keep asking why.
Learn Like A Child
Perhaps I keep mentioning children because my wife and I are expecting our daughter in the next month or so, but I find that they present a beautiful example of how to learn. Children come out of the womb as little scientists. Everything is an experiment, and anyone who has raised a child remembers the endless string of “whys” emitted by their little explorer. Data Scientists should all have this approach, but it is especially relevant to remember this when implementing Deep Learning — a field with a dizzying array of design choices that can cause the most studious Data Scientist’s mind to glaze over.
Once I test a design change with a positive effect, I try to figure out why it works. This methodology allows me to continue to improve my understanding. I may not be an expert today in a particular field, but given enough time I can always work my way towards becoming one.
I continue to ask why until I feel I truly understand the basis of choosing one design decision over another. Often one questions lead to another, and three days later you have a new and deep understanding of an array of valuable concepts. Here is a legitimate example of one rabbit hole I went down recently (do not worry if these terms do not mean anything to you):
- Why should I use an LSTM to encode my sentences?
- How does an LSTM work?
- What is the best way to regularise an LSTM?
- How should I decode the sequences from the LSTM output?
- How does Max Pooling compare with Average Pooling or using another LSTM as my decoder?
- Does a GRU perform better or faster than an LSTM? Why?
- How should I initialise my LSTM layers? Why?
- This LSTM is slow, can I speed it up?
- Why does a traditional LSTM perform so much slower than a Cuda optimised LSTM layer on GPU?
- Can I use lower precision floating points to increase the network size I can implement on my GPU?
I call them rabbit holes because the learning path is random and uncertain from the beginning. I just allow myself to explore the questions I have. I do not worry that it is haphazard, and my interest in each subject multiplies how fast and well I learn the answer. This method has been how I have learned my entire life, and I have found it always gets me to the right place (eventually). I also arrive there with a set of skills I otherwise would not if I just focused on a pre-designed plan. This approach has the downside of being time-consuming, but most Data Scientists naturally have this curiosity in them. Once I have a problem, I have to find the answer.
“Find the answer or die trying” — 50 Cent in a parallel universe
The result is that I now have a response to the first question; why I should use an LSTM to encode my sentences. Additionally, I have an answer to another set of semi-relevant questions that allow me to make new tweaks and design changes to optimise further. While testing those tweaks I might get new and novel results, so I start exploring again. If you do this long enough, you can move up the ladder from learning to experimenting, to designing, to expertise. Soon enough you might find yourself experimenting with entirely new ideas that have not been tested before.
This particular line of questioning led me to speed up my neural networks for a specific problem by four times while increasing my accuracy by 3% (which is substantial in my case). I also learned about encoder-decoder design and quite a bit about machine translation along the way. Answering my questions, rather than a pre-ordained set as is the case in traditional methods, allows me to remain focused for hours on end without exhausting my reserves of willpower.
Asking the Right Questions
Identifying the right Deep Learning problems is essential. DL is terrific at language tasks, image classification, speech translation, machine translation, and game playing (i.e. Chess, Go, Starcraft). It is less performant at traditional Machine Learning tasks such as credit card fraud detection, asset pricing, and credit scoring. Perhaps in the future, we will tweak our models, optimisation methods, and activation functions to make Deep Learning more widely applicable but for now, it is limited to the very complex.
The reason that DL performs where it does is the immense complexity it can model. With all the tasks I have identified, there are thousands, if not millions of nuances and correlations between different parts of the data. A neural net seeks out and exploits these nuances in a way that no human can. Moreover, while traditional Machine Learning can be applied to these areas, they are significantly limited in their modelling of complexity. Often Data Scientists need to spend weeks feature extracting and engineering to get a traditional model working. The reason is that the network does not have the same capability of a Deep Learning network to obtain the features on its own.
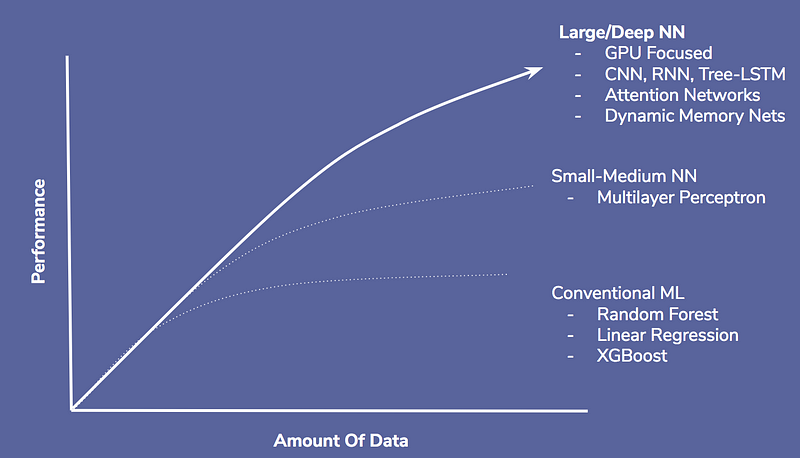
The human designer often limits traditional Machine Learning models. Deep Learning does away with much of the human constraint and allows humans to be the guide rather than the teacher. Now the model is free to explore and find its path to the solution with the help of its human developer. My job becomes giving the neural network the right tools to tear apart a problem into millions of sub-problems and then to build them back up again into a solution. It is brilliant in that it is both simple and complex at the same time.
A Healthy Dose of Paranoia
As a last, and perhaps the most crucial topic — How do you make sure your model is performing well? Unfortunately, there is not a single solution but there is a one-size fits all system that works for me.
When designing a network, I am paranoid it is not working correctly. I constantly wonder whether the scores are fooling me, or whether there are rare long-tail events that make my model look foolish. One terrible prediction can render your model inaccurate in the eyes of many. As a result, I build tools that look at the same predictions in multiple ways, make graphical tools to allow quicker iteration and faster data digestion and keep developing tools until that nagging feeling of insecurity recedes to the point of being comfortable.
Sometimes you never get there. That is why you keep tweaking, and you keep looking for flaws. Like a stubborn detective, keep prodding, testing and looking for holes. I promise you there are more than your original accuracy metrics may suggest. Look at every class individually, look at them in groups, use precision, recall, f1-score; hell, I even make them up half the time.
The point is to recognise that your model is complex, and you will only understand a portion of its decision-making processes. If you know that going in, you are much more likely to be successful going out. Your metrics lead to design changes, and your design changes lead to better models.
Sometimes you learn little niches of your model and how to control them. Sometimes you just have to accept that it does not always work. The point is often mitigation and not elimination. Any good Deep Learning system has an intelligent Quality Assurance (QA) system in the background. That QA system acts as the last line of defence against an embarrassing prediction going to a user.
By using proper QA processes, you get the metrics needed to design with purpose, learn along the way, and continuously improve yourself and your models. At the end of the day maybe all we are doing is stirring that linear algebra pot, but by doing it in a way that is driven by purpose, and understanding, our odds of success are multiplied.
This post was originally published on Towards Data Science on Jan 26, 2018: Deep Misconceptions about Deep Learning.